Bio GPT Fine-Tuning
2024. 6. 11. 17:33ㆍDL/Fine-Tuning
llama2로 판독문 데이터를 학습하였고, 더 좋은 모델을 찾기위해 여러가지 분석 후 Bio Gpt의 BioGPT-Large-PubMedQA를 선택하였다.
LLama2에서는 LoRA 기법을 사용할 때 target_modules를 정의하는 오류가 발생하지 않았지만, 다른 모델에서는 이를 정의해야 하는 경우가 있다.
특정 모듈을 업데이트해야 하는 경우, 모델의 복잡성 때문에 target_modules를 명확히 정의해야 LoRA가 올바르게 적용 됨.
즉, 모델의 구조적 차이로 인해, 특정 모듈을 명시적으로 지정하지 않으면 LoRA가 적용되지 않을 수 있음.
따라서, 모델 구조를 확인하고 레이어를 설정 함.
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.05,
target_modules=["k_proj","v_proj","q_proj"]
)
결과는 처참했다.
이해성,간결성,정확성 면에서 모든 모델에 비해 월등히 떨어졌다.
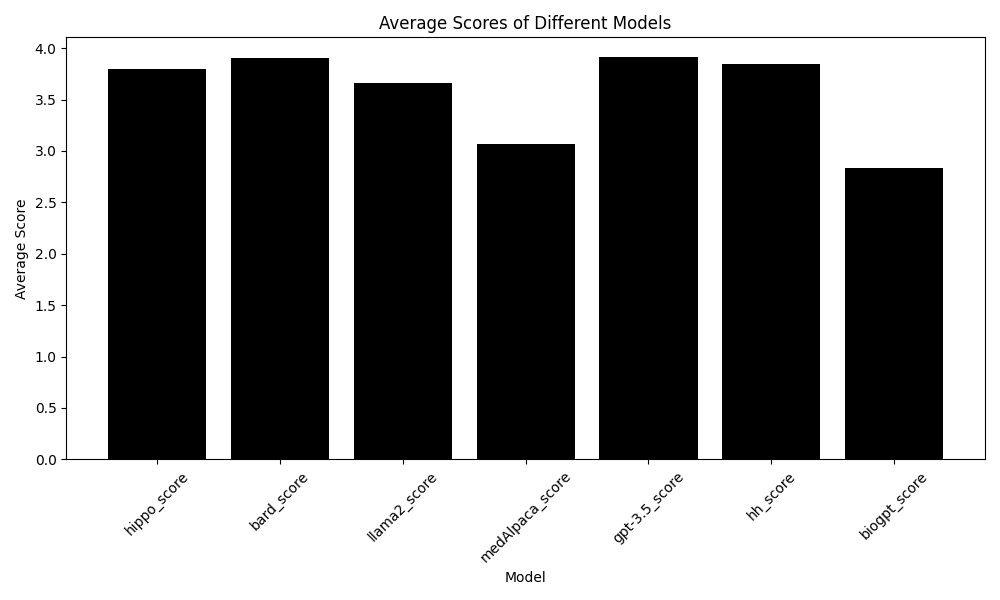
Answer를 파악한 결과 BioGPT-Large-PubMedQA에 이상한 데이터가 많이 학습된거같다.
수식, 알수없는 XML등 Answer로 나왔으며, 잘못된 데이터가 많이 사전학습된 모델인거같다.
'DL > Fine-Tuning' 카테고리의 다른 글
| RadGraph-XL: A Large-Scale Expert-Annotated Dataset for Entity and Relation Extraction from Radiology Reports (요약) (0) | 2025.09.05 |
|---|