2024. 6. 11. 16:41ㆍLLM/Paper Reading
COT는 LLM의 성능을 높이는 여러 방법 중 프롬프트를 활용하는 방법으로
주어진 질문에 대해 텍스트에서 답을 찾아 제공하는 질문 답변 (Question Answering)에서 추론 Task 성능을 끌어올리는 방법이다.
이미지를 사전에 학습시킨 모델에서 원본 이미지만 넣고 최상의 결과를 기대하지않는다.
사전에 이미지를 개선하거나, 출력된 바운딩 박스를 조정하기도한다.
이처럼 LLM도 사전 학습된 모델을 수정하지않는 상태로 특별한 학습 설정 없이 출력을, 즉 프롬프팅으로 기대하는 결과를 나오게 만들 수 있다.
COT를 리뷰하기전 대표적인 프롬프팅의 배경으로 Zero Shot, Few Shot을 볼 수있다.

Zero-Shot은 예시나 정보 없이 그대로 단답형으로 출력하는 것이라면
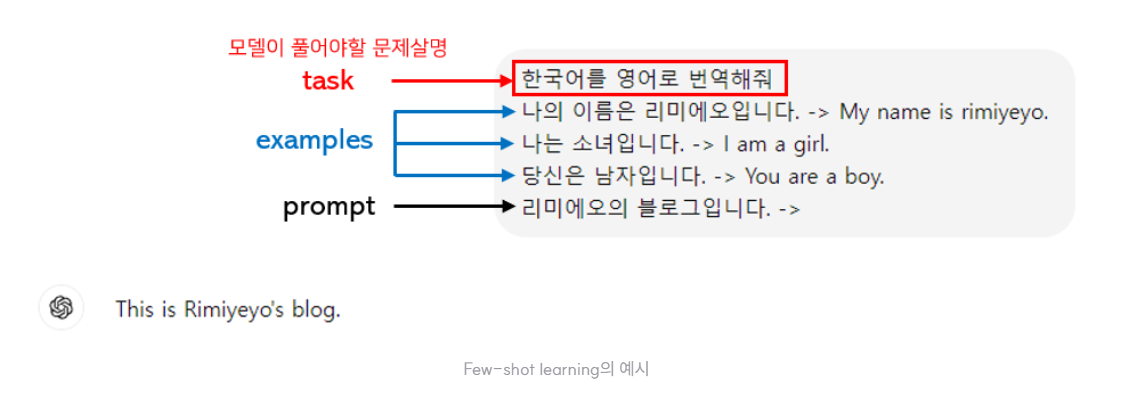
Few-Shot은 Prompt의 벡터에 대해서 유사한 토큰을 가져와서 예시로 형성하여 응답을 기대한다.
언어모델이 추론문제에서 잘 작동하지 않고, 모델 크기를 늘려도 향상되지 않던 두 한계를 극복하기 위해 input과 output 사이에 chain of thought 라는 일종의 secondary window를 제공하여 reasoning step을 직접 추가해주었다. 즉, 우리가 문제를 풀때 풀이과정을 단계적으로 적어가며 최종 답변으로 향하는 과정을 학습과정에 담았다는 것이 핵심이다. 이를 통해 언어 모델이 몇 개 안되는 예제들을 통해 추론 능력을 훨씬 상승시킬 수 있다.
산술 문제를 풀 때, 모델이 단순히 답만 생성해내도록 하는 것이 아닌, 이론적 근거(rationales)도 생성해내도록 함으로써 성능을 높일 수 있었다. 적절한 promt를 통해 모델이 답 뿐만아니라 이론적 근거도 추론할 수 있도록 하고자 한다.
산술 추론의 시험결과는 다음과 같다.
(1) Standard prompting과 Chain-of-thought prompting
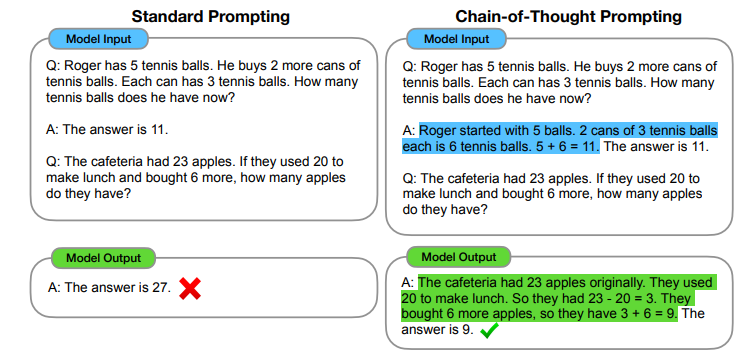
파랑색으로 하이라이트된 부분이 CoT(Chain of Thought)라 볼 수 있으며, CoT를 사용한 경우에만 수학 문제의 답을 맞춘 것을 알 수 있다.
a. standard prompting은 few-shot prompting을 의미한다. (위 figure에서 왼쪽에 해당)
b. chain-of-thought prompting은 standard prompting에 chain of thought를 추가한 것이다. (위 figure에서 오른쪽에 해당)
(2) 총 4개의 벤치마크 데이터셋(GSM8K, SVAMP, ASDiv, AQuA, MAWPS)에 대해 실험을 진행했는데, 이 데이터셋은 산술 질의응답이 담긴 데이터셋이다. 정확한 비교를 위해 chain-of-thought prompt를 만들 때 같은 입력에 대해 여러 명의 사람이 서로 다른 prompt를 만들고 하나를 골라서 사용했다.
(3) 평가는 다섯 개의 모델을 이용해 진행했다.
- GPT-3 (350M, 1.3B, 6.7B, 175B)
- LaMDA (422M, 2B, 8B, 68B, 137B)
- PaLM (8B, 62B, 540B)
- UL2 20B
- Codex
3.2 Results
(4) 주요 결과는 아래의 figure와 같다.
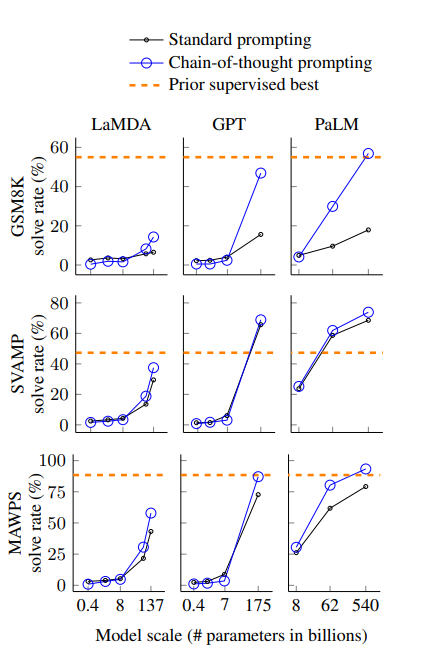
(5) 결과에서 알 수 있는 점은, 모델의 스케일이 커질수록 CoT(Chain of Thought)의 성능이 잘 나타난다는 것이다.
(6) 더하여, CoT는 복잡한 문제에 적용했을 때, 그 성능이 더 잘 나타났다. 반대로 쉬운 문제(태스크)를 할 때는 Standard prompting과 비교하여 성능이 감소하거나 적게 증가하는 모습을 보였다.
(7) PaLM 540B 모델의 경우에는 평가한 벤치마크 테스트에서 가장 좋은 성능(SOTA)를 보였다.
(8) CoT가 어떻게 작동하는지 알아보기 위해 문제를 푸는 과정에서 모델이 생성해낸 CoT를 분석해 보았다.
- 맞춘 문제 중 50개를 살펴보니, 단 2문제만 모델이 생성한 CoT에 오류가 있었으며, 나머지 문제에 대해서는 정답과 CoT에 포함된 추론 과정 역시 정확했다.
- 틀린 문제 중 50개를 살펴보니 46%의 문제는 CoT 추론 과정에서 오류가 없거나 사소한 것만 있었고, 나머지 54%의 문제는 CoT의 추론 과정에서 중요한 오류가 있었다.
(9) 흥미로운 것은 적은 파라미터 수를 가지는 모델에서 틀린 문제를 똑같은 모델에 파라미터 수만 증가시키니 정확한 CoT 추론과 함께 맞출 수 있었다. (PaLM 62B <-> PaLM 540B)
3.3 Ablation Study
(1) 본 연구에서는 CoT가 왜 성능을 높여주는지 알아보기 위해 여러 조건들을 바꿔가보며 추가적인 실험을 진행했다.

(2) Equation only : CoT를 자연어로 제공하는 것이 아닌 수식만 제공하는 방식을 사용해 성능을 테스트
- 수식만을 사용하니 비교적 복잡한 태스크에서는 성능이 좋지 않았지만, 조금 더 쉬운 태스크에서는 좋은 성능을 보였다.
(3) Variable compute only : CoT를 이용한 것이 성능이 잘 나오는게, Standard prompting 때보다 토큰 수가 늘어나 연산량이 증가한 것이 원인이 아닐까 생각해 Standard prompting에서도 '...'을 넣어 CoT 때와 토큰 수를 똑같이 맞춰주었다.
- 토큰 수를 똑같이 맞춰 연산량을 맞춰 주었는데, 여전히 CoT가 성능이 좋았다.
(4) Chain of thought after answer : CoT를 이용한 것이 성능이 잘 나오는게 CoT가 추론 과정에서 도움을 주는 것이 아닌 단순히 관련된 정보(relevant knowledge)를 더 많이 줬기 때문인가 생각해 CoT prompt를 answer 이후에 넣고 추론을 한
결과, CoT prompting을 맨 마지막에 준 것은 기존의 standard prompting과 성능이 유사했으며, 이는 추론 과정 중간에 CoT prompting을 사용하는 것이 도움이 된다는 것이다.
3.4 Robustness of Chain of Thought
(1) GPT-3의 SST-2 벤치마크 데이터셋에 대한 테스트에서는 *exemplar가 만든 prompt의 차이에 따라 성능이 54.3%에서 93.4%까지 차이가 났다고 한다.
*exemplar는 few-shot prompt, cot prompt 등을 만들어주는 사람을 의미
(2) 본 연구에서도 여러 exemplar의 prompt를 이용해 각각 학습을 해본 결과, 모든 상황에서 기존의 standard prompt보다 성능이 좋았다.
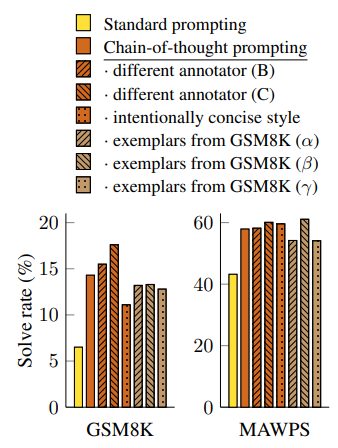
(3) 즉 annotator(= exemplar)에 대해 CoT는 robustness를 가진다고 할 수 있으며, 앞서 보았듯이 여러 다른 모델에서도 CoT가 좋은 성능을 냈으므로 모델에 대해서도 robustness를 가진다 볼 수 있다.
4. Commonsense Reasoning
(1) 상식 태스크에서는 다섯 개의 벤치마크 데이터셋을 평가에 사용하였다.
- CSQA
- StrategyQA
- BIG bench : Date
- BIG bench : Sports
- SayCan
(2) 결과는 다음과 같다.
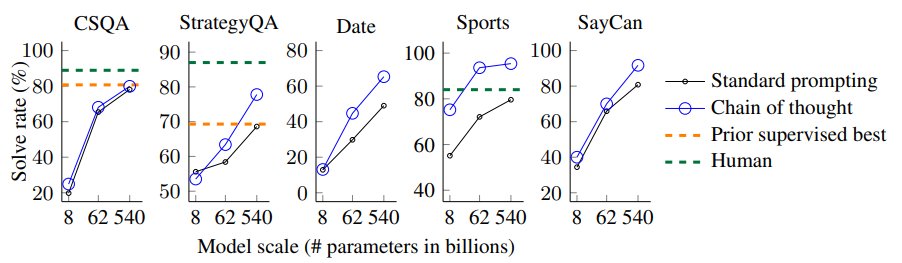
- 위 figure의 결과는 PaLM 모델에 적용한 결과이다.
- 모든 태스크에서 모델 사이즈를 증가시키는 것이 성능을 향상시켰으며, PaLM 540B 모델은 기존의 최고 성능(SOTA)을 뛰어 넘는 성능을 보여주었다.
5. Radiology GPT
(1) 판독문 GPT 기능은 약어 확장, 정의등 의료용어를 정해진 해석을 표현하는데 의의를 둔다.
즉, 판독문 자체를 해석하여 환자에게 제공하는거지, 수술방법이나 진단을 직접적으로 하지는 않아, COT와 같은 단계별로 접근하는 것은 아니라고 생각하지만, COT를 적용하여, 비교해 보았다.
(2) 적용방식은 다음과 같음.
이 부분에서는 CoT 프롬프트를 정의합니다. 여기서는 모델에게 최종 답변에 도달하기 위해 단계별 설명을 제공하도록 요청하는 문자열을 생성합니다. 즉, 모델이 논리적 단계를 통해 답변을 도출하도록 유도하는 역할
구체적으로, 사용자 역할의 대화 내용으로 message와 CoT 프롬프트가 결합된 문자열을 추가합니다.
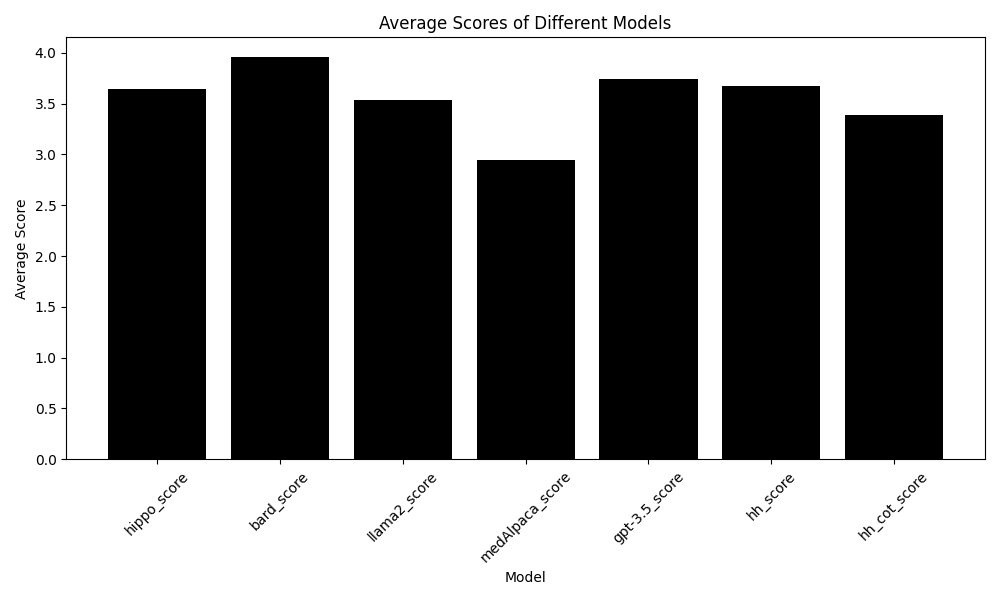
(3) Result
이해성, 간결성, 정확성 면에서 비교해보았다.

기존( hh_score: 3.85) 보다 COT 프롬프팅 (hh_cot_score: 3.52)을 적용했을 때 더 성능이 떨어졌다
간결성도 보면

이해성도 마찬가지로 떨어졌다
6. Discussion
(1) CoT를 이용한 prompting은 세 가지 분야(산술, 상식, 기호적 추론)에서 좋은 성능을 낸다.
(2) 심지어 annotator와 모델에 대해서도 robustness를 가진다.
(3) 본 연구를 통해 새로운 의문점도 생기는데, 만약 모델의 크기를 더욱 키운다면, 추론 능력을 더 향상시킬 수 있을까 하는 것이다.
(4) 한계점으로는 neural network가 정말로 인간의 추론 과정을 흉내냈다고 볼 수 것인지에 대한 대답을 내놓을 수는 없다는 것이다.
(5) 또, CoT 추론이 어떤면에서는 성능을 더 떨어트릴 수 있다고 판단하였다.
'LLM > Paper Reading' 카테고리의 다른 글
| Building Intelligent Apps withAgentic AI: Top Frameworks toWatch for in 2025 (1) | 2025.02.18 |
|---|---|
| Deep Contextualized Word Representations (0) | 2024.11.15 |
| LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale (0) | 2024.05.28 |