Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
본 리뷰는 마이크로소프트에서 발표한 Swin Transformer를 다룸.
이전 논문 리뷰에 Attention Is All You Need를 다뤘는데, 이미지의 픽셀이 늘어나면 늘어날수록 모든 Patch의 조합에 대해 self-attention을 수행하는것은 불가능해짐.
Hierarchical Vision Transformer using Shifted Windows는 한국어로 직역하면 "이동된 window를 사용하는 계층적 비전 트랜스포머"가 되는데, "계층적(Hierarchical)"은 여러 단계의 해상도나 컨텍스트를 고려하는 모델 구조를 의미하고, self-attention 계산을 위해 창(window)의 위치를 이동시키는 메커니즘임.
0. Background
Previous Problem
1. 기존 vit모델은 Classification 문제를 풀기 위한 모델로 제안
2. 텍스트와 달리 이미지를 위한 특성이 VIT에 없음
3. Token의 수가 증가함에 따라 연산량이 quadratic하게 증가
(ViT에서는 토큰의 수가 증가함에 따라 필요한 연산량이 제곱적으로(quadratic) 증가 함. 그래서 고해상도 이미지나 큰 데이터셋에 ViT를 적용할 때 계산 비용이 매우 크다 )
Purpose
1. 다양한 목적에 Backbone으로 사용될 수 있는 모델 제안( Swin Transformer는 OD, Sementic Segmentaiton에 능숙)
2. Transformer 구조에 이미지의 특성을 반영할 수 있는 방법 제안
3. 기존 VIT 모델보다 더 적은 연산량을 갖는 방법 제안
1. Solution
목적에 대한 솔루션으로, Swin Transformer에서 제안된 것인데, 가장 큰 특징은
Swin Transformer 는 Shifted Window와 Window Partitioning - Hierarchical로 나눌 수 있는데,
여기서 주요 키워드인 Window는 patches로 구성된 고정된 크기의 작은 구역이라고 볼 수 있음. Swin Transformer는 이러한 구역내에서 패치 간에 Self-Attention을 적용함.
세 단어만으로 전체적인 흐름을 보면 패치를 Window로 분할 시키고 합치고 다음 단계에서 Window를 이동시켜 분할하고 합치는 과정이라고 볼 수도 있.
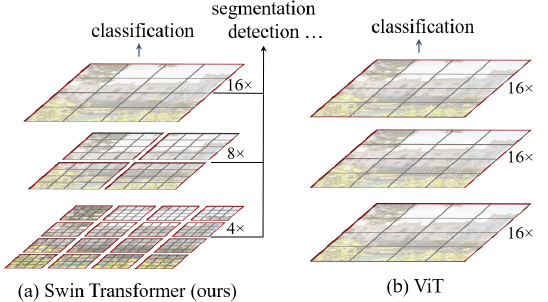
위 이미지는 Swin Transformer와 Vit의 차이점인데, Swin Transformer는 이미지의 해상도를 줄여가며 더 큰 영역의 특징을 추출할 수 있는 반면, ViT는 전체 이미지에 대해 고정된 해상도의 패치를 사용하는것을 볼 수있음.
그리고 맨아래 부분인 Window Partitioning - Shifted Window를 다뤄볼 것임.

Window Partitioning - Shifted Windows은 높은 해상도의 window를 분할하고 내부에서 self-attention하는 과정인데,
다음 이미지는 첫 번째 레이어인 Layer L 에서 Layer L+1으로 넘어갈때 어떻게 shift되는지 시작적으로 보여주는 그림임.
먼저 Window Partitioning은 이미지를 여러개의 window로 나누는 과정으로, Window Partitioning 4x4 크기의 여러 window로 분할된 첫 번째 레이어인 Layer L 에서 Shifted Windows을 수행하기 위해서 다음과 같은 파란색 과정을 거치는데,
- Cyclic Shift: (시클릭 쉬프트)(주기성 이동)
- Layer L 에서, 각 window의 패치들은 cyclic shift, 즉 순환 이동을 함. 패치 'A', 'B', 'C' 가 이동하는데, 이는 Window 경계에 위치한 인접 pixel의 정보를 고려하기 위해 Window를 M/2만큼 주기성(cyclic)있게 이동(shift)하여 self-attention을 수행하는 과정임 (M = window 내 patch 개수)
- 결국 2만큼 이동함 (다음 슬라이드)
- Masking:
- 이 shift 후에, 새롭게 구성된 window에 대해 self-attention을 계산하기 전에 특정 마스킹이 적용됩니다. 이 마스킹은 원본 이미지에서 서로 물리적으로 인접하지 않는 패치들 사이에는 attention을 계산하지 않도록 제한 함.
- 즉, shift로 인해 인접해진 것처럼 보이지만 실제로는 이미지에서 멀리 떨어진 패치들 간에는 attention 계산이 이루어지지 않도록 함. 이를 통해 모델이 잘못된 패턴을 학습하는 것을 방지함.
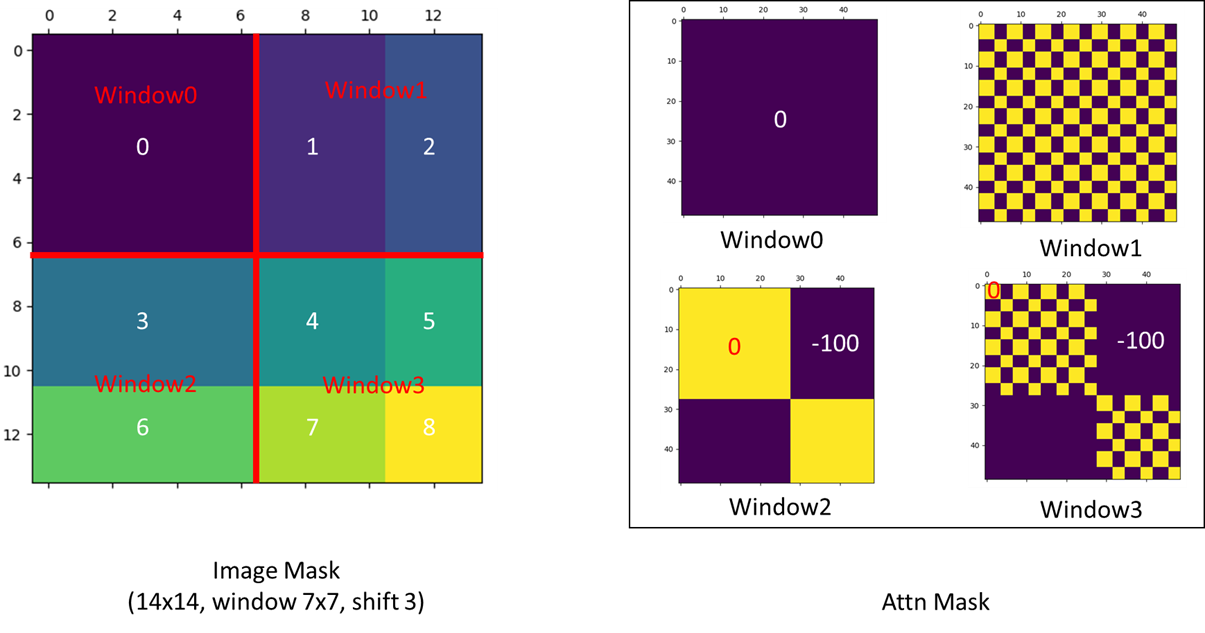
마스크 어텐션의 부연설명을 하자면, 위 이미지의 Attn Mask 를보면 14X14행렬의 window를 볼수 있는데, 새롭게 구성된 7X7로 4개의 window로 self-attention을 구성할때 자기 자신이외의 부분을 -100으로 마스킹처리하여 계산되지않는 것을 볼 수있음.
다시 돌아와서 Attention 계산이 완료된 후, Reverse Cyclic Shift 과정을 통해 실제 이미지에서 패치들의 원래 위치를 기반으로 attention이 계산될 수 있도록 하기 위해 다시 shift 전상태로 돌아감.
즉, attention의 결과를 패치들이 원래 있던 공간적 위치에 맞게 재배열 함.
특정 stage 그러니까 여기서 stage는 n번째 shift 단계인데, stage의 마지막 layer에서 self-attention과 필요한 모든 연산이 완료된 후, 다음 stage로 넘어가기 전에 패치들을 합칩니다. 이 과정은 모델의 깊이에 따라 여러 번 반복될 수 있으며, 각 stage의 시작 부분에서 해상도를 점진적으로 낮춥니다. 패치를 합치는 과정을 통해, 더 큰 영역의 정보를 포착할 수 있는 더 큰 패치가 생성되며, 이 과정을 Hierarchical 라고 함.
2. Method

먼저 Swin transformer의 구조를 보면 VIT와 다른점이 Position Embedding이 없다는 점임. Swin transformer는 이러한 과정이 없고, self-attention을 수행하는 과정에서 self-attention 연산에서 상대적인 위치 정보를 고려하는 relative position bias를 추가함.

위의 식을 보면 일반적인 attention score 구하는 식 뒤에 bias인 B를 더해줌. bias 행렬을 더하여, 각 패치의 상대적인 위치를 고려 함.
Swin Transformer는 4개의 stage로 구성되어 있으며, 각 stage는 입력 이미지의 해상도를 점진적으로 낮춤.
이는 'Merge' 라는 과정을 통해 수행되며, 이 과정에서 인접한 패치들이 하나의 큰 패치로 합쳐짐.
해상도가 낮아질수록, 모델은 더 큰 영역의 이미지 특징을 처리할 수 있게 됨.
먼저 Patch Partition 과정을 거치게 됨.
여기선 먼저 ViT와 같은 patch splitting module을 이용해 non-overlapping patch로 RGB 이미지를 나누어 줌.
여기서 나눠진 patch는 token으로 사용되고 이 feature는 raw pixel의 RGB 값을 이어 붙인 것이 됨.
즉 patch가 4*4로 나누어진다면 RGB value를 곱해주어 최종적으로 4*4*3 = 48 dimension을 가지게 된다.
- stage 1 - Linear Embedding
이후 linear layer를 통하여 H/4 * W/4 * 48 텐서를 H/4 * W/4 * C 텐서로 변환 함.
특정 차원 C를 선택함으로써, 모델의 크기와 계산 복잡성을 조절할 수 있으며,
C는 model의 크기에 따라서 달라지게 됨.
이후 Patch Merging layer로 Stage에 따라 주변 patch를 병합하면서 token의 개수를 줄여나가게 됨.
- stage 2~4 - Patch merging
처음 4*4 크기의 작은 patch들을 점점 합쳐가며 계층 구조를 만드는 과정임.
- 패치 합치기:
- 위에 언급했듯 각 패치는 원래 C 차원의 특징 벡터를 가지고 있음.
- 인접한 2×2 패치를 합치게 되면, 4개의 C 차원 벡터가 하나의 4C 차원 벡터로 합쳐짐.
- 해상도 감소:
- 원본 이미지를 H/4 × W/4 크기의 패치로 나누었을 때, 각 패치는 원본 이미지의 1/16 면적에 해당 함.
- 인접한 2×2 패치를 하나로 합칠 때, 이 면적은 4개의 패치가 하나로 합쳐져 원본 이미지의 1/64 면적이 됨.
- 따라서, 합친 패치의 해상도는 원본 이미지의 H/8 × W/8이 됨.
- 특징 차원 증가:
- 4개의 C 차원 벡터를 합친 결과는 4C 차원 벡터임.
- 이 4C 차원 벡터에 선형 변환(Linear Layer)을 적용하여 차원을 2C로 줄임.
- 선형 변환은 4C 차원 벡터를 입력으로 받아, 가중치 행렬을 곱한 후 2C 차원 벡터를 출력 함.
- 패치 합치기:
- Swin Transformer block
주목할 점은 처음 block에서는 Window Multi-head Self Attention(W-MSA)를 통과하고 그다음 block에서는 Shifted Window based Multi-haed Self Attention(SW-MSA)를 통과하게 됨.
각각 2-layer MLP, Layer Norm(LN), GELU를 통과하게 된다.
Shifted Window based Self-Attention

기존 self-attention(MSA)은 모든 query와 key set에 대해 연산을 해야 돼서 해상도가 높아짐에 따라 계산 복잡도가 제곱에 비례해 매우 커짐.
M(window size)는 h*w(image size)에 비해 훨씬 작기 때문에 연산량이 적고 image size가 커지더라도 ViT에 비해 연산량을 줄일 수 있음.
하지만 window가 fix 되어 있기 때문에 self-attention시에 고정된 부분만을 수행한다는 단점이 있어 window를 shift 하여 한번 더 self-attention을 수행해서 문제를 해결하였음.
식 (1)과 식 (2)를 비교할 때, 두 식 모두 첫번째 항을 가지고 있음. 이는 입력 특징들에 대한 변환(키, 쿼리, 밸류 계산)과 관련된 연산량을 나타 냄.
차이점은 두 번째 항에 있음.
- 식 (1)에서 2(hw)2C 은 전체 이미지에 대한 Multihead-self-attention 을 나타 냄. 이 항은 이미지 크기의 제곱에 비례함.
- 식 (2)에서 2M2hwC 은 각 윈도우 내의 Multihead- self-attention 을 나타 냄. 이 항은 윈도우 크기의 제곱에 비례하며, 이미지의 전체 크기 에 대해서는 선형적으로 증가 함.
어텐션 연산 감소는 이 ℎ에 비해 훨씬 작기 때문에 발생 함. 식 (1)의 두 번째 항에서는 전체 이미지의 크기에 대한 제곱이 연산량을 결정하는 반면, 식 (2)에서는 작은 윈도우 크기 에 대한 제곱만이 윈도우 내의 연산량을 결정 함. 따라서, 식 (2)의 두 번째 항은 식 (1)의 두 번째 항에 비해 훨씬 작아서, 전체적으로 W-MSA가 MSA보다 연산량이 적다는 것을 나타 냄.
3.Experiments
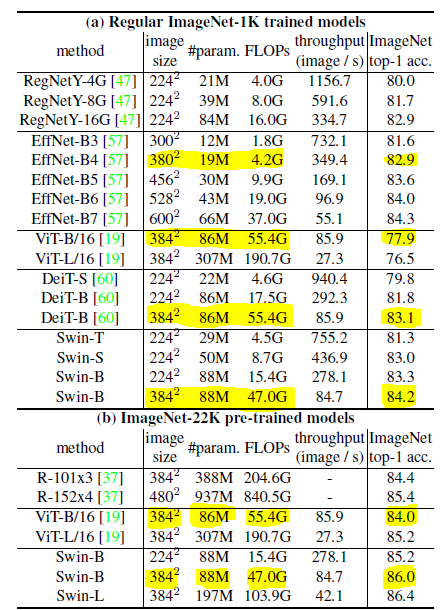
ImageNet 데이터셋에 대한 성능 비교를 보여주고 있는데, 특히 Swin-B 모델은 384^2 이미지 해상도에서 84.2%의 Top-1 Acc.를 달성하여 뛰어난 성능을 보여주고 있습니다. Swin Transformer 모델들은 vit에 비해 비교적 적은 파라미터 수(#param)와 FLOPs에도 불구하고 높은 정확도를 달성함을 확인할 수있음.